SPO三元组是知识图谱中用于表示知识的基本单元,其中S(Subject)代表主体(即知识的承载者,通常是实体),P(Predicate)代表谓词(即主体与客体之间的关系),O(Object)代表客体(即与主体相关联的实体或属性值)。
例如:
- 在“小明是学生”中,S为“小明”,P为“是”,O为“学生”;
- 在“北京位于中国”中,S为“北京”,P为“位于”,O为“中国”。
通过SPO三元组的组合,可构建出结构化的知识网络,清晰展现实体间的关联,是知识图谱存储和表达知识的核心方式。
知识图谱是由一条条知识组成,每条知识表示为一个SPO三元组(Subject-Predicate-Object)。
- 知识图谱实际上就是如此工作的。曾经知识图谱非常流行自顶向下(top-down)的构建方式。自顶向下指的是先为知识图谱定义好本体与数据模式,再将实体加入到知识库。该构建方式需要利用一些现有的结构化知识库作为其基础知识库,例如 Freebase 项目就是采用这种方式,它的绝大部分数据是从维基百科中得到的。
- 大多数知识图谱都采用自底向上(bottom-up)的构建方式。自底向上指的是从一些开放链接数据(也就是 “信息”)中提取出实体,选择其中置信度较高的加入到知识库,再构建实体与实体之间的联系。
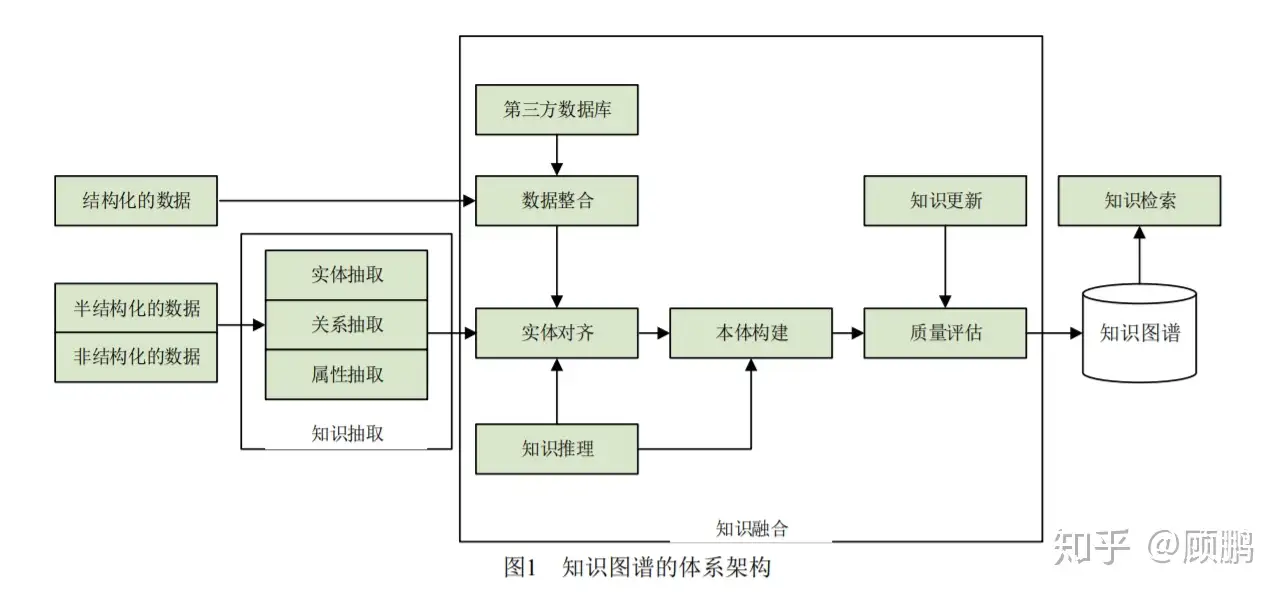
- 大规模知识库的构建与应用需要多种智能信息处理技术的支持。通过知识抽取技术,可以从一些公开的半结构化、非结构化的数据中提取出实体、关系、属性等知识要素。通过知识融合,可消除实体、关系、属性等指称项与事实对象之间的歧义,形成高质量的知识库。知识推理则是在已有的知识库基础上进一步挖掘隐含的知识,从而丰富、扩展知识库。分布式的知识表示形成的综合向量对知识库的构建、推理、融合以及应用均具有重要的意义。
知识抽取有三个主要工作:
- 实体抽取:在技术上我们更多称为 NER(named entity recognition,命名实体识别),指的是从原始语料中自动识别出命名实体。由于实体是知识图谱中的最基本元素,其抽取的完整性、准确、召回率等将直接影响到知识库的质量。因此,实体抽取是知识抽取中最为基础与关键的一步;
- 关系抽取:目标是解决实体间语义链接的问题,早期的关系抽取主要是通过人工构造语义规则以及模板的方法识别实体关系。随后,实体间的关系模型逐渐替代了人工预定义的语法与规则。
- 属性抽取:属性抽取主要是针对实体而言的,通过属性可形成对实体的完整勾画。由于实体的属性可以看成是实体与属性值之间的一种名称性关系,因此可以将实体属性的抽取问题转换为关系抽取问题。
推荐文章
- 2.2.20250803 KG笔记法 (1.000)
- 5.1.20250711 维基百科 (0.778)
- 2.3.20250816 双链 (0.778)
- 2.2.20250720 知识图谱 (0.722)
- 8.1.20250720 知识图谱实体统一的方法 (0.722)
- 5.1.20250711应用-美团外卖 (RANDOM - 0.500)